How to find and replace in SSMS using regex option
To take out blank lines (as when you import code from Firefox sometimes) find
\n @\n
… and replace with
\n
To find all instances of INT that aren’t commented out try
^~(:b–).:bINT>
(this is an example of a good use for a negative look-behind to check that the line isn’t commented)
To select up to the first hundred characters in a line
^(.^100)|(.*)
This will try to select 100 characters from the start of the line, and only if it fails, it will select all of them
To insert a string at a particular column position
^{.^100}
And replace with..
\1’I’ve inserted this’
(or whatever!) This simply matches a line with 100 characters and replaces the first hundred characters with the first hundred characters plus the string you want to insert.
To delete ten columns after column 100 use this
^{(.^100)}{.^10}
Replace with
\1
What would happen if you used \2\1? Yeah. Useful once in a while!
To find either a quoted string or a delimited string, use
(“[^”]“)|([[^[]])
To replace all quoted strings with quoted delimiters, find
(“{[^”]*}”)
… and replace with
[\1]
This shows how to create a capturing group using {}, and use it in the replace expression. It can also be used in the find expression
To remove inline comments that take the whole line, find
^:b–.$
… and replace with nothing
Here, we are using a greedy quantifier * to find the entire comment line (line starting with –)
To find any valid object name with delimiters
[{[A-Za-z_#@][A-Za-z0-9#$@_]*}]
to take out the quoted delimiters [ and ] where they aren’t necessary, replace with
\1
This illustrates the use of character class definitions to determine whether the delimited strings contains only characters that are valid in a SQL identifier.
To find ‘tibbling’ (use of tbl, vw, fn, or usp prefixes) use this
<(tbl|vw|fn|usp)[A-Za-z0-9#$@_]*>
Here we show one of the most useful of constructs, where alternative strings to search for are listed. It also shows how the special ‘<’and ‘>’ characters are used to delimit the start and end of a word.
To de-tibblize code, us this
<(tbl|vw|fn|usp){[A-Za-z0-9#$@_]*}>
… and replace with …
\1
Here we add a capturing group (Microsoft calls them tags) to capture the word without the tibblizing prefix. (add your own to taste!)
To match any word at least 3 characters long, you can use
<:c^3:c*>
This is one of the workarounds for the lack of proper range quantifying. It is the equivalent of {n,} in normal RegEx
To find multi-line comments using /* / use this /*(:Wh|[^:Wh])*/
Normally, RegEx strings will stop searching at the end of the line if you use the standard wildcard. This RegEx uses a trick to get around that.
To find a Title-cased word (word starting with a capital letter followed by lowercase)
<:Lu:Ll[a-zA-Z0-9_$]*>
Microsoft have some convenient shorthand characters to represent character classes. Here we illustrate their use with the :Lu:LI
To take out the headers that SMO puts in like
/ Object: StoredProcedure [dbo].[uspGetBillOfMat] Script Date: 01/07/2011 19:03:05 /
find this,
/[*]^6.[*]^6/ replace with nothing This shows the simplest quantifier. We use the [*]^6 to represent six stars *
to comment out lines, select the lines, Make sure you have ‘Look in selection’ and find
^
replace with
To un-comment outlines, select the lines, Make sure you have ‘Look in selection’ and find
^:b–{.}$
replace with
\1
To find two words separated by up to three words (in this case FROM and AS) use
With normal syntax, you’d use \b FROM (?:\W+\w+){1,3}?\W+AS\b but we have no range quantifiers, so we are forced to use the ascending alternatives (descending if we want to be greedy rather than lazy). This becomes ridiculous if we want to specify the quantifiers for complex expression. We’d have to duplicate the long-expression.
To find the first object that is referenced by a FROM clause (doesn’t successfully avoid strings or multiline comments), use
^~(:b–.){(:Wh|[^:Wh])#}<(ON|CROSS|RIGHT|INNER|OUTER|LEFT|JOIN|WHERE|ORDER|GROUP|AS)>
here you have something that is looking for a whole lot of different alternative keywords merely by grouping them and using the | character to.
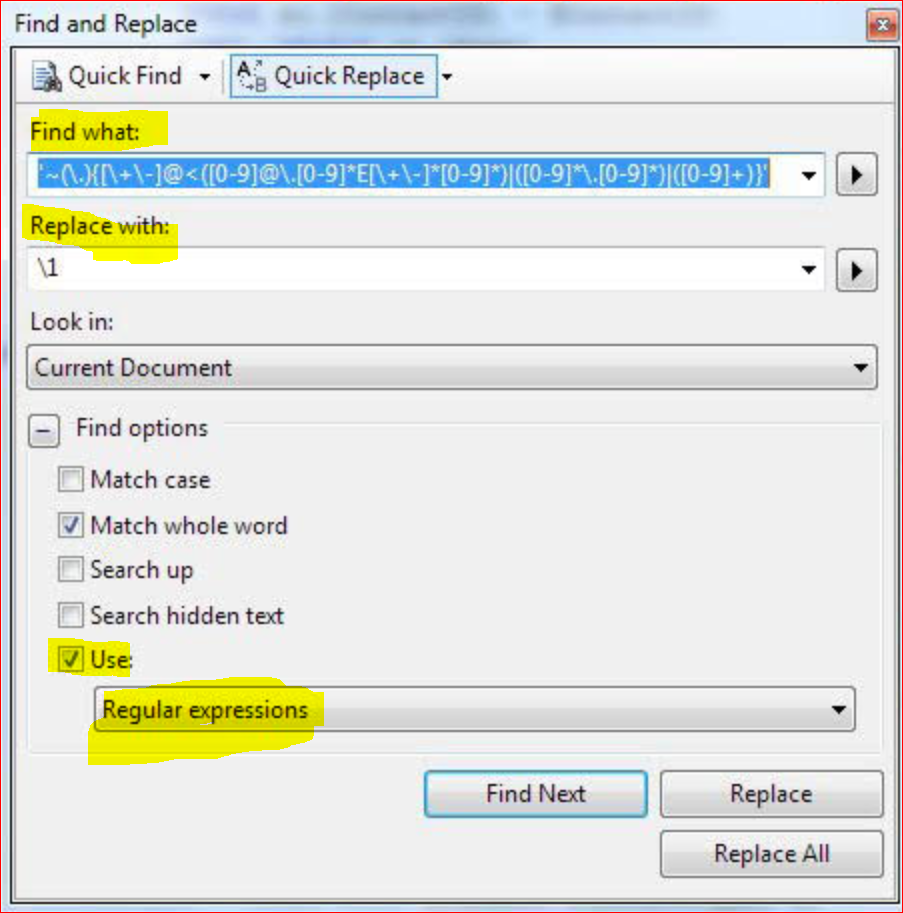
To find either an integer or a floating-point number, one can use the following RegEx which is a bit long but simple in structure
~(.)<([+-]@[0-9]@.[0-9]E[+-][0-9])|([+-]@[0-9].[0-9]*)|([+-]@[0-9]+)
This starts at a word boundary that is not preceded by a dot. It first looks for a floating-point number in exponential notation. then it looks for a number in conventional notation before finally trying for an integer.
Metacharacters outside square brackets
| Standard | VS and SSMS | Examples | Meaning |
| \ | \ | \n means end of line, \\ means backslash | general escape character (the next character as either a special character, a literal, a backreference, or an octal escape.) only [\^$.|?*+() have special meanings and have to be escaped |
| ^ | ^ | ^– finds a SQL comment line | assert start of the string (or line, in multiline mode) |
| $ | $ | GO$ finds GO at the end of a line | assert (anchors) to end of a string (or line, in multiline mode) |
| . | . | ^.* finds the next line | match any character except newline (by default) |
| [ | [ | [0-9] specifies any character between 0 and 9 | start character class definition These definitions are by default case sensitive |
| ] | ] | [a-z@] (any character between a to z or a “) | End character class definition |
| | | | | <(outer|cross)>[^:a]#<apply> (finds all instances of OUTER or CROSS APPLY. | start of an alternative branch (the OR or PIPI operator) |
| ( | ( | start sub-pattern | |
| ) | ) | (ON|OFF) (finds either ‘ON’ or ‘OFF’) | end sub-pattern |
Quantifiers
| ? | 0 or 1. Can also mean ‘quantifier minimizer’ Also used after a bracket to extend its meaning | ||
| * | * | 0 or more -greedy | |
| + | 1 or more -greedy (also “possessive quantifier”) | ||
| ?? | lazy zero or one | ||
| *? | @ | favo[u]@rite matches both favorite and favourite (and favouuurite) | lazy zero or more (matches as few as possible) |
| +? | # | lazy one or more | |
| {n} | ^n | [\@]^2 (matches @@Identity but not @identity) | N is a positive integer. Matches exactly n times. |
| {n,} | N is a positive integer. Matches at least n times. | ||
| {n,m} | Range specifier. M and n are positive integers, where n <= m. Matches at least n and at most m times. | ||
| ? | When this character immediately follows any of the other quantifiers (*, +, ?, {n}, {n,}, {n,m}), this specifies that the matching pattern is lazy, in that it matches as little of the searched string as possible. Otherwise it matches as many as poassible. | ||
| . | . | Wildcard: . Matches any single character except “\n”. |
Metacharacters inside square brackets (In a character class )
| \ | \ | [\\\*] (either a backslash or star) | general escape character |
| ˆ | ˆ | [^\@\#] (not an ampersand or hash char) | negate the class, but only if the first character |
| – | – | [0-9A-F] (valid hex digit | indicates character range |
| ] | ] | End character class definition | |
| [ | [ | POSIX character class |
Non-Printing characters in strings
| \b | \h | Match a backspace | |
| \t | \t | Match a tab character | |
| \r | Match a carriage return character Equivalent to \x0d and \cM. | ||
| \n | \n | Match a line feed character Equivalent to \x0a and \cJ. | |
| \a | \g | Match a bell character | |
| \e | \e | Match a escape character | |
| \f | Match a form feed character Equivalent to \x0c and \cL. | ||
| \v | Match a vertical tab character | ||
| \x## | \x## | \xD8 (0xD8 – 216 decimal) | Match the ASCII or ANSI character with position in the character set (Hexadecimal escape values must be exactly two digits long). |
| \u#### | \u#### | \u0106 (U+0106 in unicode table) | Match the Unicode character that occupies code point in the Unicode character table |
Generic Character types (character classes)
| \w | :a | \@:a* finds next variable | Match a single character that is a “word character” (letters, digits, and underscores) Equivalent to ‘[A-Za-z0-9_]’. |
| \W | [^:a] | <SET>[^:a]*[:a]*[^:a]*<(ON|OFF)> (finds all SET xxx On or OFF statements) | Match a single character that is a “non-word character” c.f. [^A-Za-z0-9_] |
| \d | :d | level:dname (finds Level0name, levl1name etc) | Match a single digit 0..9 |
| \D | [^:d] | Match a single character that is not a digit 0..9 | |
| \s | :Wh | Match a single character that is a “whitespace character” (spaces, tabs, and line breaks) Equivalent to [ \f\n\r\t\v]. | |
| \S | [^:Wh] | Match a single character that is a “non-whitespace character” | |
| [0-1] | Match a single character in the range between “0” and “1” Character range: Matches any single character in the range from first to last. | ||
| [a-zA-Z] | [a-zA-Z] | Match a single character present in either in the range between “a” and “z” or between “A” and “Z” | |
| [^a-zA-Z] | [^a-zA-Z] | Match a single character that is not present in either in the range between “a” and “z” or between “A” and “Z” | |
| [Chars] | [Chars] | Match a single character present in the list “Chars” | |
| [\p{L}\p{P}] | Match a single unicode character eithee any kind of letter from any language (L) or Punctuation (P) |
Assertions (Anchors)
| \A | Assert position at the beginning of the string | ||
| \z | Assert position at the very end of the string | ||
| \Z | Assert position at the end of the string (or before the line break at the end of the string, if any) | ||
| ^ | ^ | Assert position at the beginning of a line (at beginning of the string or after a line break character) -this meaning outside a character class only | |
| $ | $ | Assert position at the end of a line (at the end of the string or before a line break character) | |
| \b | (<|>) | Assert position at a word boundary | |
| \< | < | <DECLARE> finds the word DECLARE | Assert Start of word |
| \> | > | Assert end of word | |
| \B | ~(<|>) | Assert position not at a word \b boundary | |
| \G | Assert position at the end of the previous match (the start of the string for the first match) |

